The client, a Public Equity firm, wanted the TresVista team to create a dataset of active securities per period for the last 40 years for a set of 14-15 geographies using Cap IQ screens. The client wanted the team to determine the primary exchanges for each geography, create a dataset free of survivor bias, and remove data inconsistencies using Python. Further, the team was asked to automate the process of fetching fundamental and market-related data for each security using CapIQ mnemonics for excel. Additionally, the team was told to automate the data ingestion into multiple custom-built excel VBA-based backtesting templates.
To find the primary exchanges, automate the process of making a survivor bias-free database, fetch KPIs using CapIQ mnemonics and finally automate the data pipeline so that data is available for slicing and dicing, and running multiple backtesting strategies.
The TresVista Team followed the following process:
The major hurdle faced by the TresVista Team were:
The team overcame the hurdles by building algorithms to clean the data, identifying how and which variables impacted the whole database pull, and then attempting optimizations to reduce the time database takes to refresh the list of active securities by geographies. This was done, ensuring the strategy followed was not altered. The team also understood how the database stores the data and the multiple ways it links to different data points.
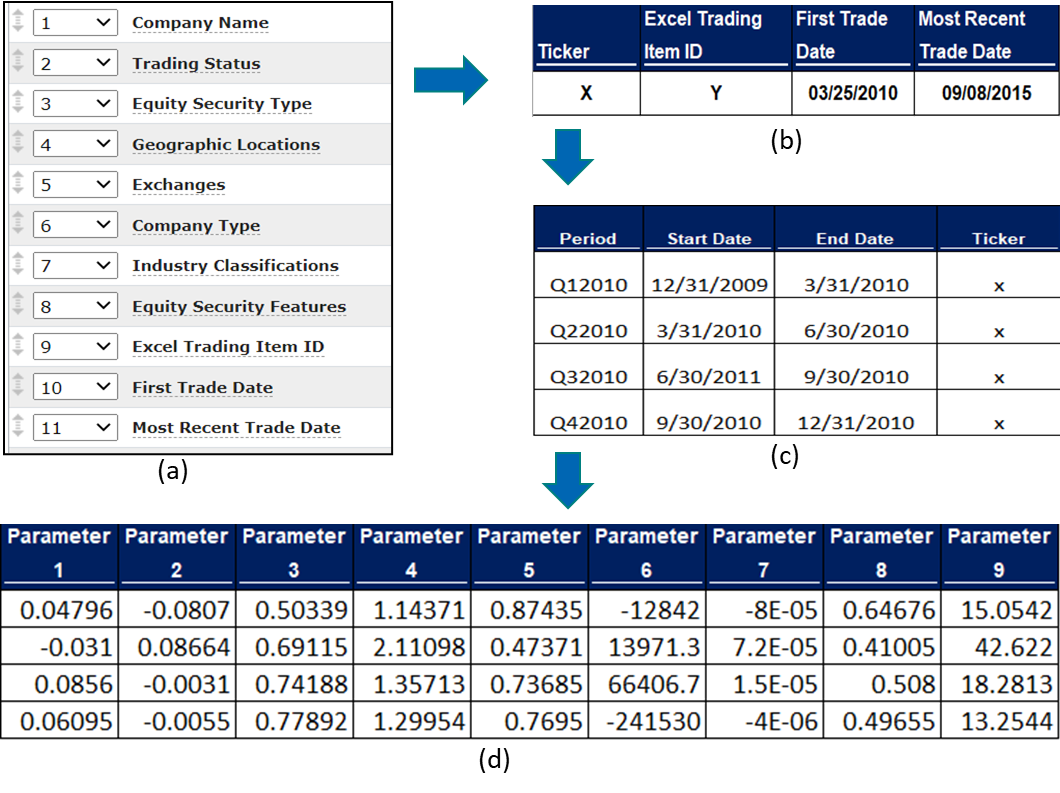
The TresVista Team automated ~95.0% of the whole database creation process. The automation now takes one click to get all the trading periods for a security. The team also provided 100.0% security coverage across geographies and exchanges that the client had fetched. Further, the team tweaked the CapIQ data pull that reduced the data fetching time by ~40.0 minutes. Additionally, the team created databases of multiple periodicities for the client to test the hypothesis at any level of data granularity.







