The Context
The client, a Hedge Fund with ~$700 million in assets, wanted the TresVista Team to automate the entire process of their monthly fund summary report creation. Earlier, the monthly fund performance reports were created by pulling data from the client’s accounting system, manually copy-pasting into MS-Excel, and then creating the required charts/table. Manual creation of these reports was a time-consuming process which was prone to errors and created a lag in the reporting process. Further, performing daily-level calculations manually on the entire dataset was complex, which resulted in the client reporting only monthly numbers in the charts.
The Objective
To create an automated data pipeline gathering data from the accounting system and other internal sources, perform calculations, and store in a format suitable for processing by the web development team. The objectives were:
- Develop, extract, transform, and load (ETL) data pipeline
- Check for data discrepancies and standardize the data
- Perform metrics calculations based on business logics
- Visualize dynamic fund reports on the client’s Duda website
- Schedule periodic data refresh on a monthly basis
The Approach
The TresVista Team followed the following process:
- Datasets from multiple sources and varied frequencies were collated and reshaped in the required format using Python
- The collated data was cleaned and pre-processed removing inconsistencies, and was ready to be stored in the MySQL database
- Set of business logics were applied using Python to create backend data which will form visuals reflecting patterns, growth percentages, and other important metrices that play a key role in making appropriate business decisions
- The data was then accessed by the vendor for creating visuals
- Automation of the process by scheduling periodic fund summary refresh in first week of every month
The Challenges We Overcame
The major hurdle faced by the TresVista Team were:
- In the dataset there were many cases where historical data was not recorded consistently into the accounting system. This lead to inconsistencies between calculated vs. reported values. The TresVista Team hard-coded the values at places where the inconsistencies could not be resolved because of historical data availability
- There were few datasets which were not part of the accounting system and were sourced from multiple stakeholders. Historically, these were not recorded in a consistent format and were often unstructured. The TresVista Team created standard templates for the manual data inputs, so that the process can be automated going forward. Unstructured historical data was compiled manually as a one-time exercise
- Categorization of securities was not consistent across the timeline. For mapping of securities to their respective categories, the TresVista Team identified patterns in the data and leveraged RegEx-based pattern matching to obtain the correct mappings
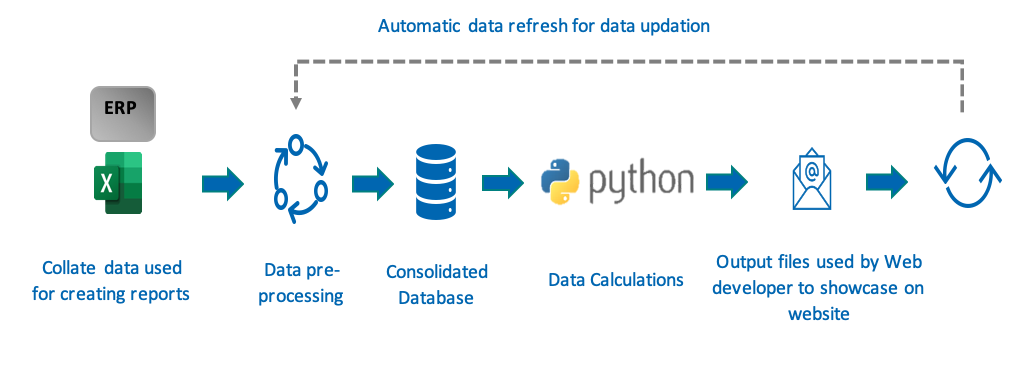
Final Product (Sanitized)
Report Sample
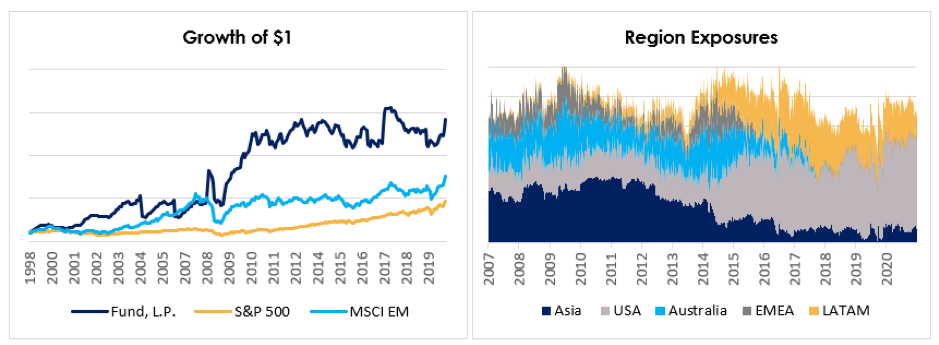
Process Flow